Recently, federated learning has attracted great interest from the research community under the umbrella of distributed machine learning. It protects the privacy of data by learning a shared model using distributed training on local client devices without collecting the data on a central server. Distributed intelligent agents take a shared global model from the central server’s parameters as initialization to train their own private models using personal data, and make predictions on their own physical devices.
Federated learning learns a shared global model by the aggregation of local models on client devices. But simple federated averaging only uses a simple average on client models, ignoring the contributions of different models. For example, in the mobile keyboard applications, language preferences may vary from individual to individual. The contributions of client language models to the central server are quite different. To learn a generalized model that can be quickly adapted to different people’s patterns and preferences, knowledge transferring between server and client, especially the well-trained clients models, should be considered.

Fig 1. Aggregation with the consideration of model importance
We introduce an attention mechanism for model aggregation. The intuition behind the federated optimization is to find an optimal global model that can generalize the client models well. In our proposed optimization algorithm, we take it as finding an optimal global model that is close to the client models in parameter space while considering the importance of selected client models during aggregation.
Attentive federated aggregation is proposed to automatically attend to the weights of the relation between the server model and different client models. The attentive weights are then taken to minimize the expected distance between the server model and client models. The advantages of our proposed method are: 1) it considers the relation between the server model and client models and their weights, and 2) it optimizes the distance between the server model and client models in parameter space to learn a well-generalized server model.
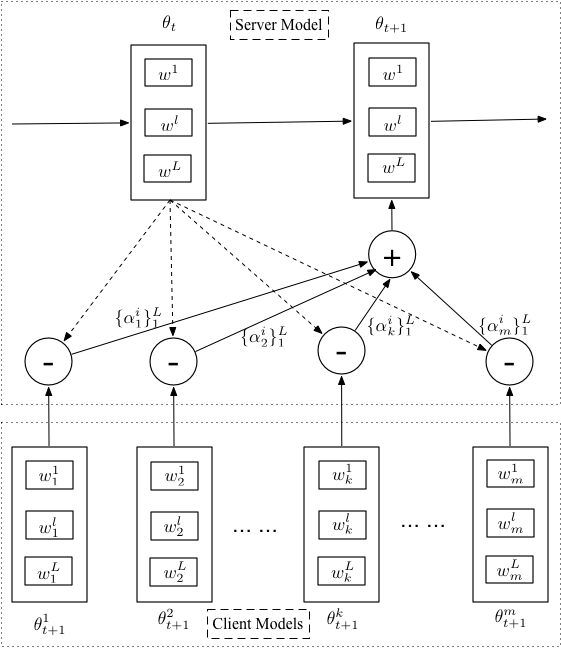
Fig 2. Attentive Federated Learning
Experiments of private language modeling task are conducted to mimic personalized mobile keyboard suggestion. Mobile keyboard suggestion as a language modeling problem is one of the most common tasks because it involves with user interaction which can give instant labeled data for supervised learning. We choose GRU as the local learner because it is a simple RNN variant with less parameters than LSTM, which can save communication cost to some extent. In practice, the mobile keyboard applications predict the next word with several options when a user is typing a sentence.
Publications
Decentralized Knowledge Acquisition for Mobile Internet Applications.
Jing Jiang, Shaoxiong Ji, and Guodong Long.
World Wide Web Journal, 2020.
Learning Private Neural Language Modeling with Attentive Aggregation.
Shaoxiong Ji, Shirui Pan, Guodong Long, Xue Li, Jing Jiang, and Zi Huang.
2019 International Joint Conference on Neural Networks (IJCNN), 2019. [Code]
Feature image was token by Shaoxiong Ji in Alibaba Xixi Park, Hangzhou, Zhejiang, China.
{kind=link}